LAMP Extracting Text from Gradients with Language Model Priors
LAMP: Extracting Text from Gradients with Language Model Priors
1、它解决的问题
- 现在大多数成功的数据重建攻击基本都是计算机视觉领域的任务,文本领域的工作相对少之又少,尽管事实上,一些最突出的FL应用涉及对文本数据的学习,例如,移动电话[30]上的下一个单词预测。针对文本的攻击少
- 这些计算机视觉领域的攻击之所以能够成功是利用了一些图像的先验如总的方差,然而到目前为止文本攻击还没有使用先验,这限制了他们重建真实客户端数据的能力。(这一点也暗示了作者可能会使用一些文本数据的先验)目前文本攻击没有充分利用先验
2、主要贡献
- LAMP是一种用于从梯度中恢复输入文本的新型攻击,它利用辅助语言模型来指导对自然文本的搜索,以及交替进行连续和离散优化的搜索过程。
- LAMP的实现及其广泛的实验评估,表明它可以比以前的工作重构更多的私人文本。我们在https://github.com/eth-sri/lamp上公开了代码。
- 第一次全面的实验评估文本攻击在更复杂的设置,如更大的批量大小,训练好的模型和防御模型。
- 他们不用假设知道标签(现在已有的工作通常强假设知道标签)
3、它的方法
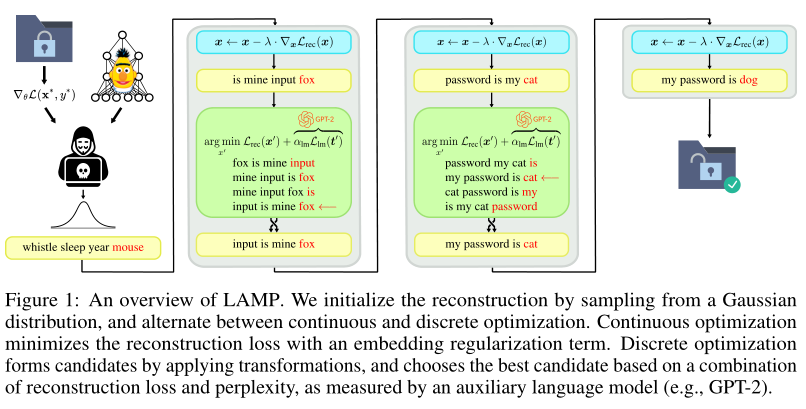
首先通过从高斯分布采样来初始化重建目标,并在连续和离散优化之间交替进行。连续优化算法通过优化被攻击数据使得重建损失(如式子(1))最小。离散优化通过转换当前最优的重建数据形成候选,并根据重建损失和困惑度的组合(由辅助语言模型(例如GPT-2)测量)选择最佳候选。
- 连续优化:
重建损失: (1)
其中通常是指或者损失
- 离散优化:
- Swap:我们在序列中均匀随机地选择两个位置和,并在这两个位置交换符号和,以获得一个新的候选序列。\
- MoveToken:类似地,我们在序列中均匀随机地选择两个位置和,并将token 移动到序列中位置的后面,从而得到。
- MoveSubseq:我们均匀随机地选择三个位置, 和(其中),并在位置之后移动和之间的子序列。因此,新的序列为。
- MovePrefix: 我们随机地统一选择一个位置,并将结束于位置的序列的前缀移动到序列的末尾。修改后的序列是。
最终算法:

4、它存在的问题
标签默认已知
学到的知识:
-
基于差分隐私的工作确实训练了具有正式保证的模型,但通常会损害训练模型的准确性,因为它们需要在梯度中添加噪声。
-
tokenization:对text/log进行分词。tokenization:对text/log进行分词
-
one-hot vector:
-
例如存在词向量[i, you, like, apple, banbana]
1
2
3
4
5i:[1, 0, 0, 0, 0]
you:[0, 1, 0, 0, 0]
like:[0, 0, 1, 0, 0]
apple:[0, 0, 0, 1, 0]
banana:[0, 0, 0, 0, 1] -
对某个样本某个人的特征进行编码:
性别特征[“男”,“女”],对应[1, 0]。
祖国特征:[“中国”,"美国,“法国”], 对应[1,0,0]。
运动特征:[“足球”,“篮球”,“羽毛球”,“乒乓球”], 对应[0,0,0,1]。
完整的特征数字化的结果为:[1,0,1,0,0,0,0,0,1]。这样就把特征转化为了向量,便于特征之间距离的计算和相似度的计算。
-
-
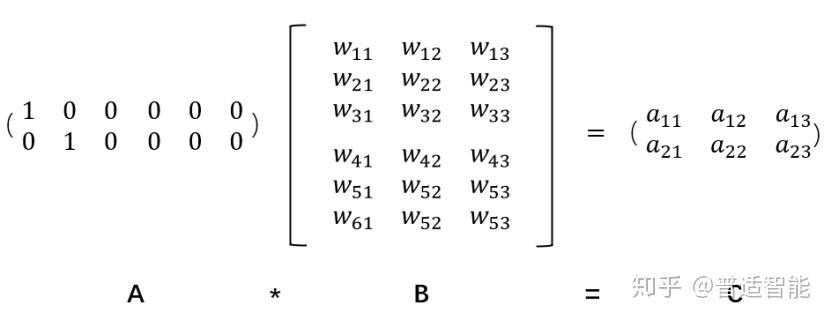
Embedding对one-hot降维
-
困惑度(Perplexity)-评价语言模型的好坏
简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率?那么如何计算一个句子的概率呢?给定句子(词语序列)它的概率可以表示为:
也就是说在给定一句话的前k个词,我们希望语言模型可以预测第k+1个词是什么,即给 出一个第k+1个词可能出现的概率的分布。
注意:
-------------本文结束感谢您的阅读-------------